


System Design Interview - Building the Backend for a News In Shorts App (Part-1)
S1E1 - Backend of News Aggregator

Hey everyone, and welcome to Episode 1- (Part 1) of system design interview series!
We will go through a series of real time System Design Questions & answers. Today I will design News In Shorts application along with how to answer in real interview setting.
This exact question came up in a Google system design interview back in April 2025. We'll break it down step by step, covering requirements, architecture, and NFRs like scalability and low latency. Let's dive in and level up your interview game! 🚀
Due to length of the System Design Answer, I have divided the answer in two parts.
Problem Statement
Design the server side of a news-serving mobile app that sequentially shows news cards, each with a 100-word summary of the news and an image.
News are aggregated from other web sites and the user can tap on a news to be redirected to the original article.
If you want to understand how to answer the SD Interview questions, you can follow the format explained in my other article below. I am following same format here as well.

Before anything else, understand the question and clarify the requirements. This is a crucial step in any system design interview. Interviewers often present vague problems, and they expect you to ask relevant questions to gain clarity.
1. Clarifying Requirements (2 mins)
Summarisation: How is the "100-word summary" generated? Is it the first 100 words of the article, or is it an intelligent, extractive summary?
Assumption: We need an intelligent summarisation service (likely using an ML model) to create a meaningful summary, not just a truncation.
Content Sources: Where are we getting the news from? Are we crawling news websites, using RSS feeds, or partnering with news APIs (like the Associated Press, Reuters) or a web-hook mechanism from news sources?
Assumption: We will primarily use RSS feeds and partner News APIs, as this is more reliable and respectful than aggressive web scraping.
Scale: How many users are we designing for? How many news sources?
Assumption: Let's design for a scale of 100 million daily active users (DAU) and aggregating from thousands of sources.
Personalisation: Is the news feed the same for everyone, or is it personalized?
Assumption: For now, let's assume the feed is the same for all users in one region, with personalisation as a potential future enhancement.
Geographic availability : Is it global or limited to a specific region?
Assumption: We'll initially assume the app is available in one region, with global expansion as an extension down the line.
Freshness: How quickly does a newly published article need to appear in a user's feed?
Assumption: For breaking news, freshness is critical. We should aim for a glass-to-glass latency of under 15 minutes from publication to appearing in the app.
Write down the answers to the questions in drawing tool itself (I am using excalidraw)

Next step is to list down Functional Requirements explicitly on drawing tool or board.
2. Functional Requirements (3 minutes)

Though it is practically impossible to create the whole system in 60 mins interview. Ask interviewer if they want to add/delete anything
3. Non Functional Requirements (3 minutes)
Non-Functional Requirements define how the system should perform under various conditions, including increased load and distributed environments.
Our system prioritises scalability (thousands of sources, millions of articles daily) and high availability (99.99% for the feed API, with eventual consistency for new content).
We need low latency reads (p99 < 200ms) for a smooth user experience and fault tolerance so single article processing failures don't halt the system. Finally, data freshness (low end-to-end pipeline latency) is crucial.

We layout Data model and api to map relevant FR . However, ask your interviewer if they prefer to skip to High-Level Design.
4. Data Model Design (2 minutes)
Here's a smooth way to respond without getting stuck early on:
"I’ll jot down an initial data model based on what’s top-of-mind. We can refine this as we dive deeper into requirements and trade-offs."
Why this works: It shows proactive thinking while keeping the conversation flexible.
Then, sketch something simple :

5. API Design (3 minutes)

Always communicate to your interviewer that you will come back on to these if any modification is required.
Aim to reach here in 13-15 minutes
6. High Level Design (10-15 minutes)
In this section, we'll outline the High-Level Design (HLD), mapping it directly to the core Functional Requirements (FRs) like news ingestion, processing, feed generation, and delivery.
A) The News Ingestion & Processing Pipeline (Write Path)
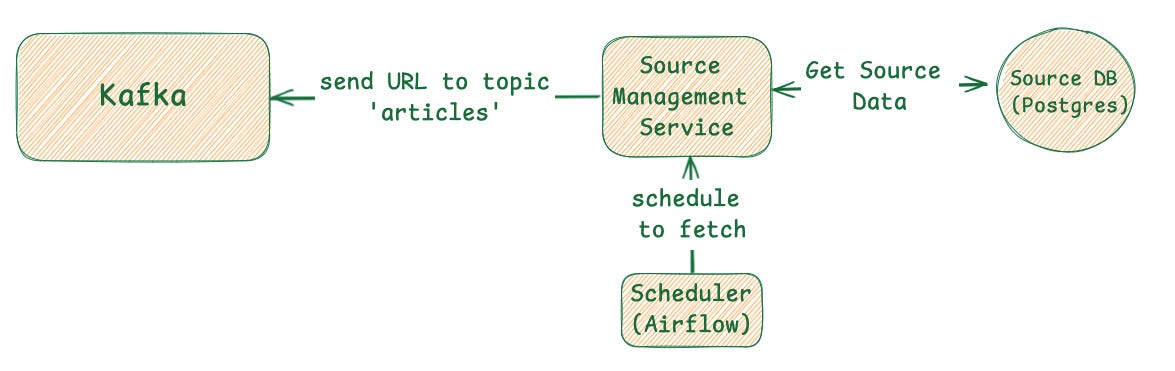
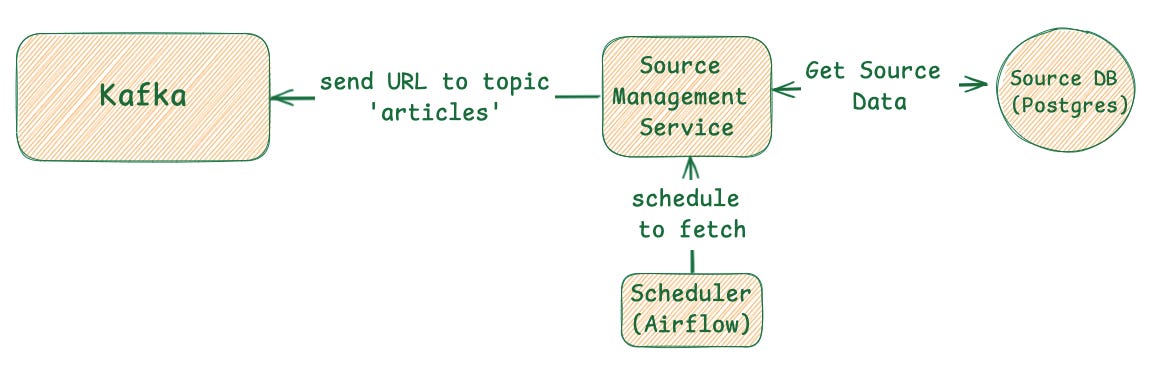
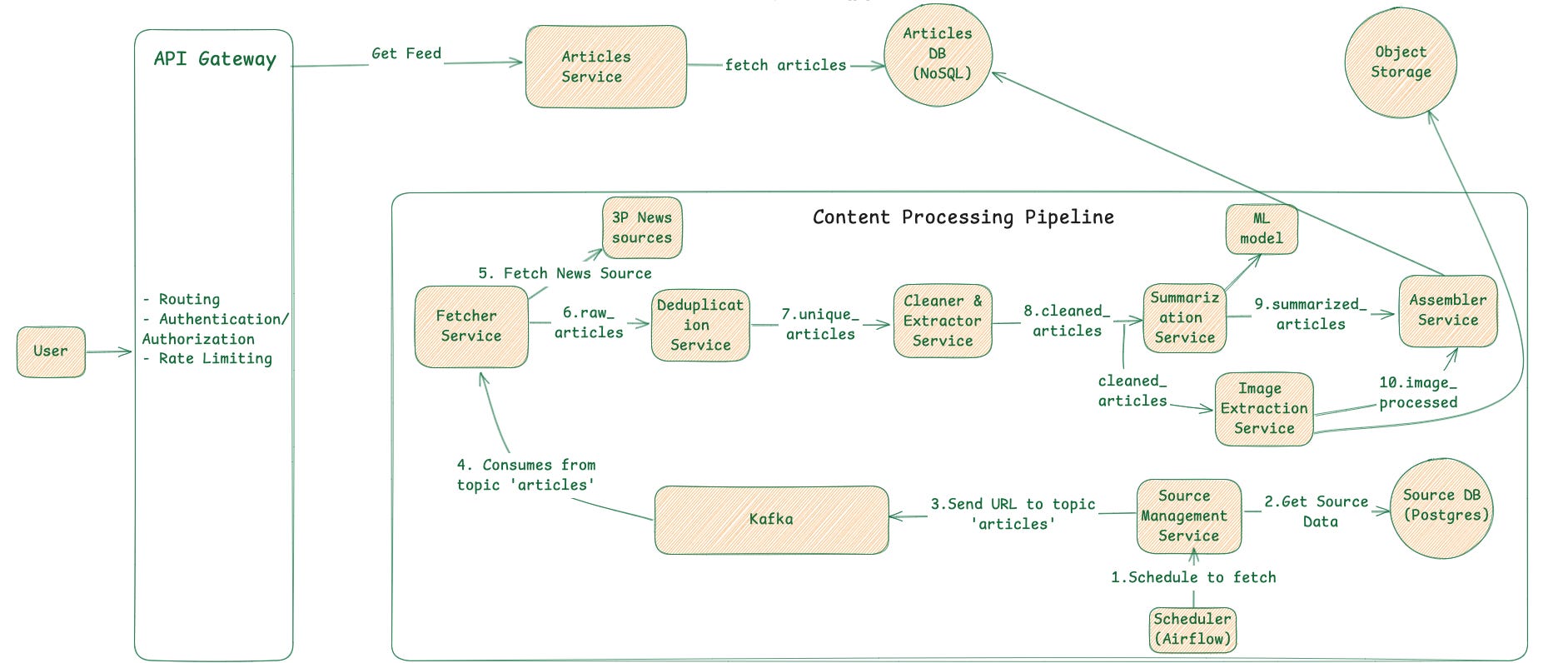
Step 1 (Scheduling): A Scheduler (like Apache Airflow) orchestrates the entire process. It maintains a schedule for when to check each news source.
Step 2 (Aggregation): We will design a dedicated micro-service Source Management Service with its own database (a relational db like PostgreSQL is a perfect fit here) to store metadata about each of 1,000+ news sources. A scheduler will periodically query this service to determine which sources need to be fetched.
Step 3 (Decoupling): Each new URL is published as a message to a Message Queue (like Kafka). This crucial step acts as a durable buffer, decoupling article discovery from complex analysis. It ensures no incoming articles are lost, even if downstream services are temporarily offline.
This is how diagram looks like :
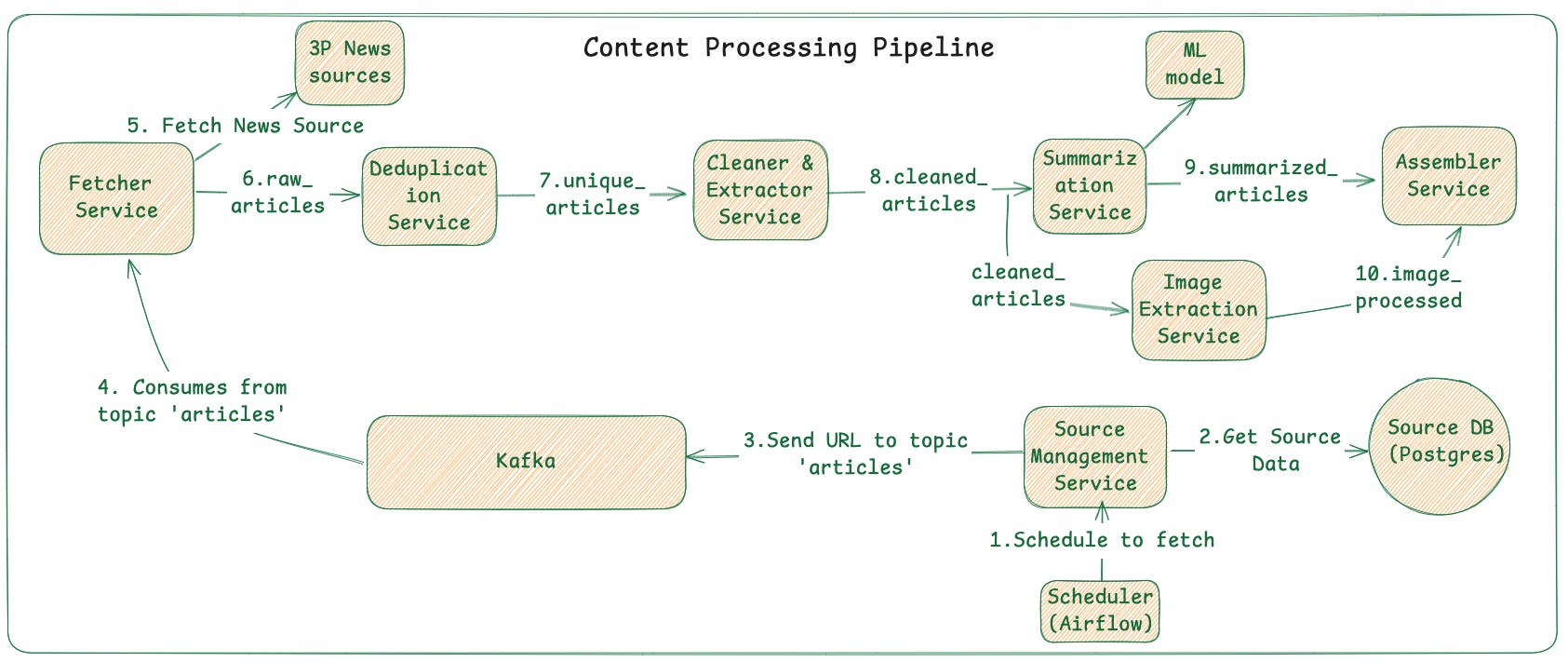
Step 4 (Processing): Our pipeline will consist of a series of independent micro-services, each performing a single, well-defined task. Each service consumes messages from one Kafka topic and, after processing, produces new messages to the next topic in the chain.
Fetcher service: Gathers raw articles and sends them to the
raw_articlestopic.Deduplication: Consumes from
raw_articles, removes duplicates, and outputs tounique_articles.Content Cleaner: Consumes from
unique_articles, extracts the core text from HTML/XML, and sends it tocleaned_articles.Summarisation & NLP: Consumes from
cleaned_articles, generates a summary and tags (keywords, topics) by using ML model, then outputs tosummarised_articles.Image Extractor: Finds and processes the main article image from
unique_articles, storing it in Object storage (S3) and sending the URL to theimage_processedtopic.Assembler & Storage: Consumes from
summarised_articlesandimage_processed, combines the text and image data, and saves the final article to a database.
Below is a detailed diagram. It’s ok if you miss some intermediary service. Important ones are Fetcher, Summarisation, Image Extraction & Assembler services
The Feed Serving API (Read Path)
Step 1 (Request): The mobile app makes a
GET /v1/feedrequest to our API Gateway.Step 2 (Feed generation ): The request is routed to the Articles Service. It then queries the
articlesdatabase for a set of recent, high-quality articles from the user location which includes the image url stored in object storage(S3).Step 3 (Feed click) : The feed already contains the url. On click of feed phone will open the url in web view.
I have updated the diagram and included feed serving path.
In Part -2 I will cover the following topics:-
Back-of-the-Envelope Calculations
Deep-dives
Enhancements
Stay Tuned !! ❤️
Stay tuned for more dive deeps on Real-World System Design Problems. Let me know in comments if you want me to solve some specific Design Problem.
And hey, don’t forget to follow me on Linkedin for more insights and updates. Let's stay connected!